Der Einsatz von Redaktions- bzw. Content-Management-Systemen (CMS) ist mittlerweile zu einem echten Breitenthema geworden. Der Markt der Anbieter hat sich formiert und sortiert. Die Systeme sind dabei über die Jahre gereift und haben eine Vielzahl von Funktionen aus einer noch größeren Anzahl von realen Projekten und Implementierungen hinzugewonnen. Sie unterscheiden sich aber in zahlreichen wichtigen Details und haben auch in der Anwendung durchaus verschiedene Schwerpunkte. Grundlage ist aber immer das Denken und Arbeiten in modularen Einheiten, in der Wiederverwendung von Inhalten und in der Unterstützung wichtiger Prozesse. Letztere umfassen das Varianten-, Versions- und Übersetzungsmanagement sowie vielfältige Publikationsmechanismen für alle aktuell benötigten Medien und Formate.

Soweit so gut; dennoch es ist nicht immer einfach für Unternehmen, die Möglichkeiten, aber auch die eigenen Aufgaben zu erkennen, die mit einer Einführung eines CMS zusammenhängen; und dann auch noch zu erkennen, welches der verfügbaren Systeme zu den eigenen Anforderungen am besten passt.
Eine Hilfe zu all dem soll der PI-Fan bieten. Unter diesem Namen verbirgt sich ein Referenz-Modell für modulare und klassifizierte Inhalte. Weniger abstrakt gesprochen: Der PI-Fan ist eine frei verfügbare Sammlung von modularen Texten samt Grafiken, mit denen eine ganze Palette von Ventilatoren (englisch „Fan“) zusammengestellt werden können. Das Besondere: Die Module tragen Metadaten, die mit der Methode der PI-Klassifikation definiert wurden. Diese mittlerweile häufig verwendete Klassifikationsmethode sorgt dafür, dass für Redakteure ein eindeutiges Modulkonzept definiert werden kann und für die jeweilige CMS-Anwendung eine klare Planung der notwendigen Informationen möglich ist.
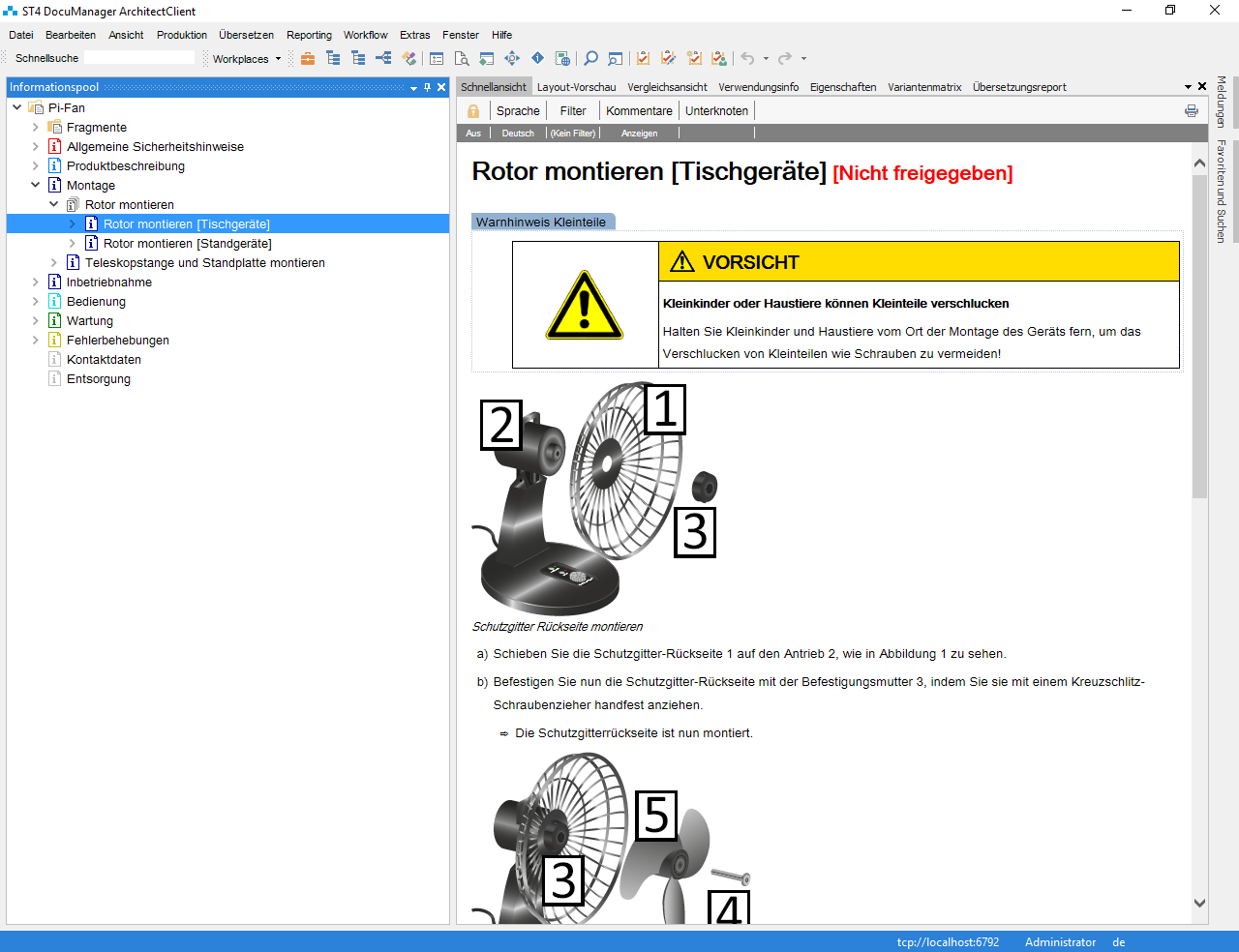
Im Download-Paket des Steinbeis-Transferzentrums I4ICM sind hierzu prototypisch alle notwendigen Planungsdateien als Excel-Matrizen hinterlegt und erlauben ein rasches Verständnis der verwendeten Metadaten sowie des Zusammenfügens von Modulen zu Dokumenten.
Die Bezeichnung PI kommt übrigens von der zweifachen Sichtweise auf modulare Inhalte bzw. auf die zu erstellenden Dokumente: P umfasst die Produkt- und I die Informationsfestlegung. So wird jedem Modul eine eindeutige (Fachjargon „intrinsische“) PI-Klassifikation zugewiesen: jeder modularen Inhalte muss sich auf eine der Produktkomponenten („Rotor“, „Heizung“,) beziehen und darf nur eine der im Unternehmen vorab definierten Informationsklassen („Wartung“, „Reparatur“, „Funktionsbeschreibung“,) trennscharf enthalten. Die Verwendungsmöglichkeiten der Module für Endprodukte werden (über sogenannte „extrinsische“ Metadaten) den Varianten der Lüfter-Baureihen und den verschiedenen Dokumentarten zugeordnet.
[Für Experten: Es sind natürlich auch weitere Variantenmerkmale zum Filtern im PI-Fan eingebaut und nutzbar]
Mit diesen Beispieldaten können nun Systemhersteller alle vorhanden Möglichkeiten ihres Systems demonstrieren. Automatisches Zusammenbauen von Dokumenten bzw. Filtern mit Hilfe der Klassifikationen ist nun ein Leichtes und für die an CMS Interessierten durchgängig und in verschiedenen Systemen zu betrachten.
In SCHEMA ST4 sind die (PI-)Klassifikationen am direktesten über die Taxonomie-Funktionalität abbildbar. Im Allgemeinen folgen nämlich sowohl intrinsische als auch extrinsische Metadaten einem hierarchischen Aufbau und Logik. Dem Entsprechend können auch die Variantenfilter die Nutznießer der hierarchischen Klassifikation sein und können alle möglichen Szenarien der Dokumenterstellung und der Publikationsprozesse aufzeigen.
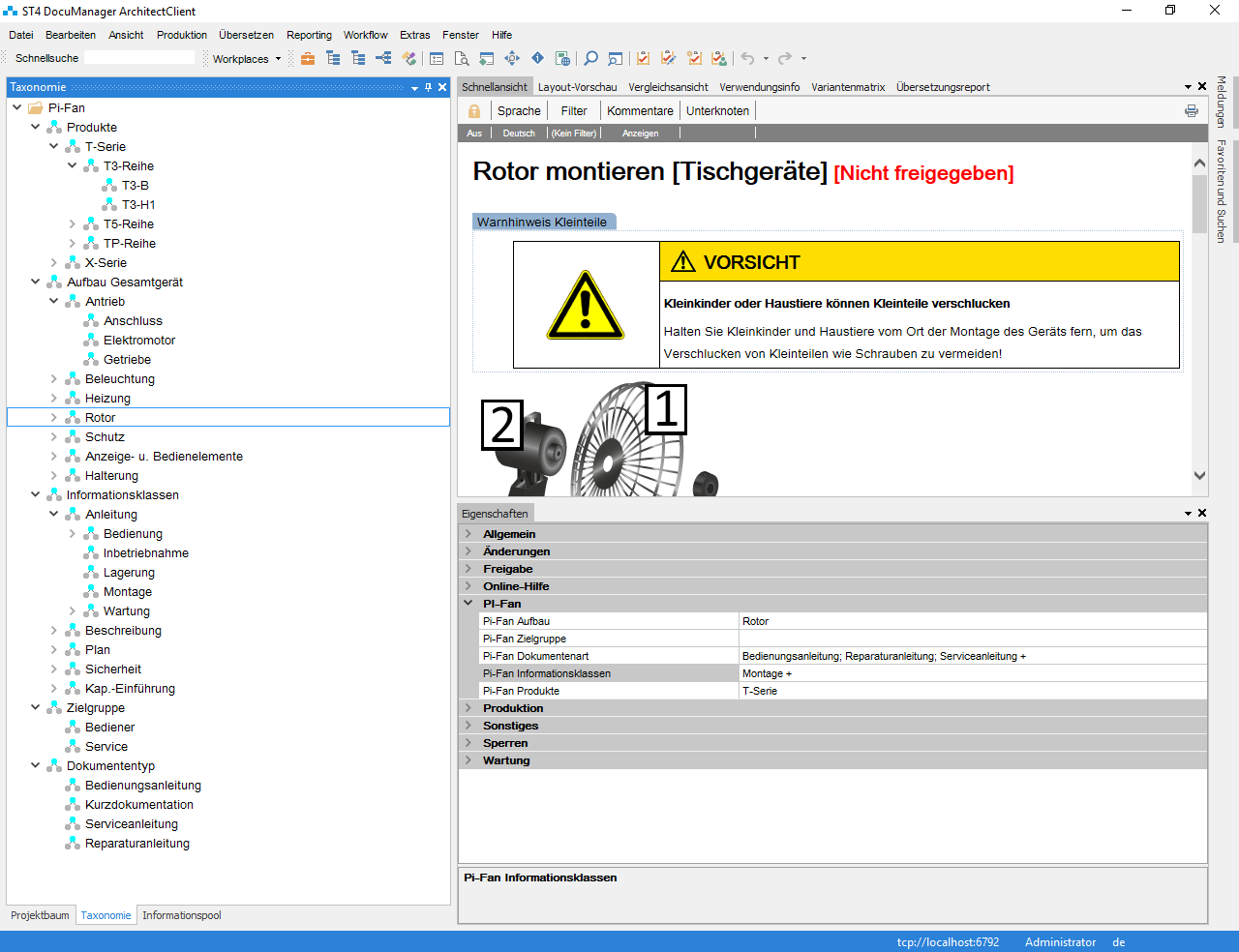
Die PI-Klassifikation wird im Bild oben über Taxonomien realisiert.
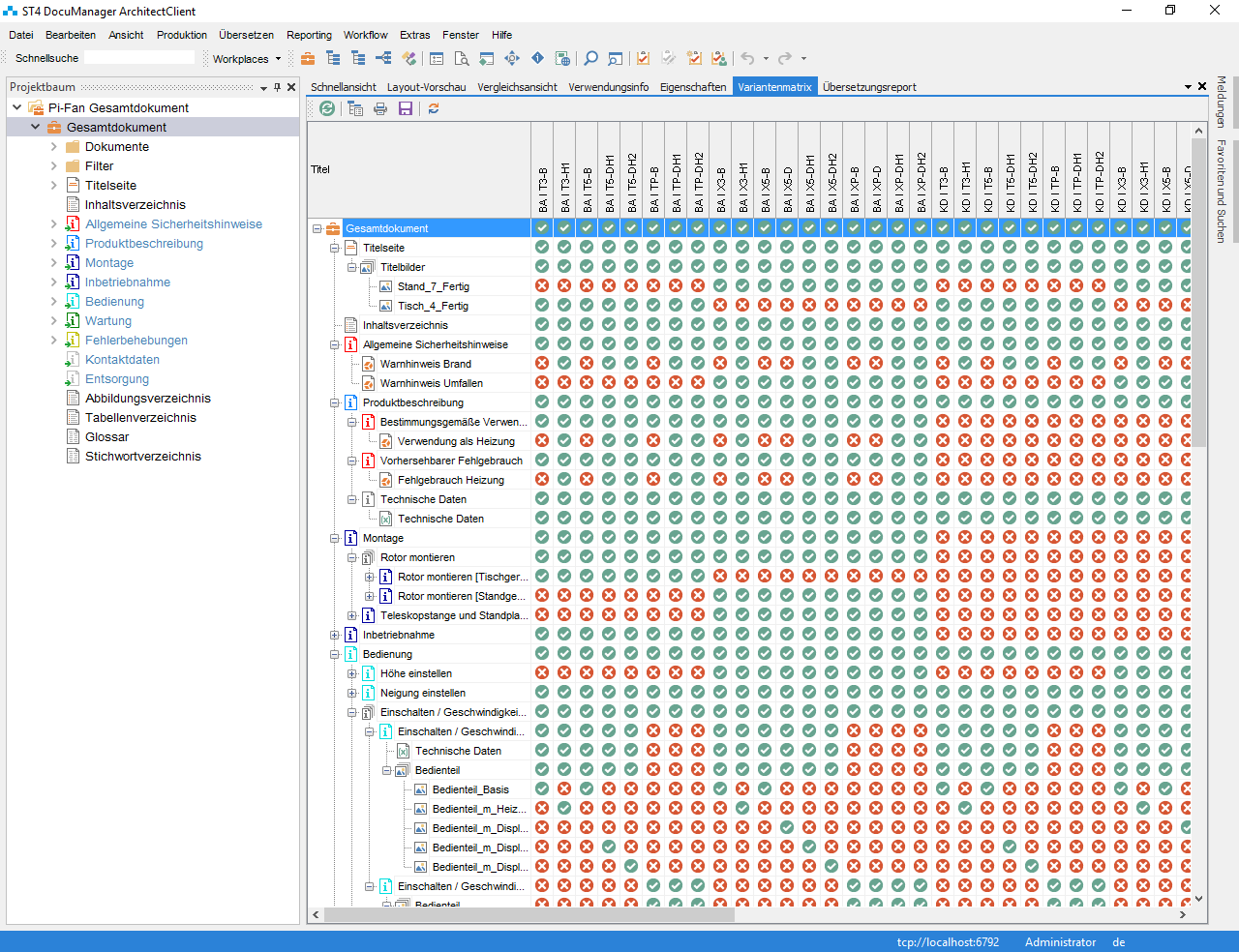
Variantenbildung für 72 verschiedenen Dokumente
Um die jeweilige Umsetzung des PI-Fans zumindest in Bildern kennenzulernen, stehen Screenshots und ggf. zukünftig auch andere Medien und Links auf der Website des Steinbeis-Instituts zur Verfügung. Eine ausführliche Demonstration können dann alle Anbieter jeweils live stattfinden lassen.
Spannend wird es dann noch, wenn die PI-Klassifikation und die 72 möglichen PI-Fan- bzw. Dokumentvarianten in den neuartigen Content-Delivery-Portalen (CDP) zu finden sind. Die Klassifikationen werden hier nämlich als Facetten oder Suchfilter genutzt und die Portale lassen die generierten (HTML-)Dokumente als Ganzes navigierbar erleben oder eben zielgerichtet modular darstellen. Natürlich sind auch bereits Anbieter (u.a. SCHEMA mit dem Content Delivery Server) mit dem PI-Fan diesen Weg gegangen und stellen ihn für alle Delivery-Interessierten anschaulich dar. Es ist daher zu erwarten, dass der PI-Fan auch auf dem Content-Delivery-Symposium 2016, auf dem viele wichtige CDP-Anbieter ihre Lösung vorstellen, zu finden ist.
Prof. Dr. Wolfgang Ziegler
wolfgang.ziegler@i4icm.de
www.i4icm.de
Institut für Informations- und Content-Management (I4ICM)
Steinbeis Transferzentren GmbH an der Hochschule Karlsruhe
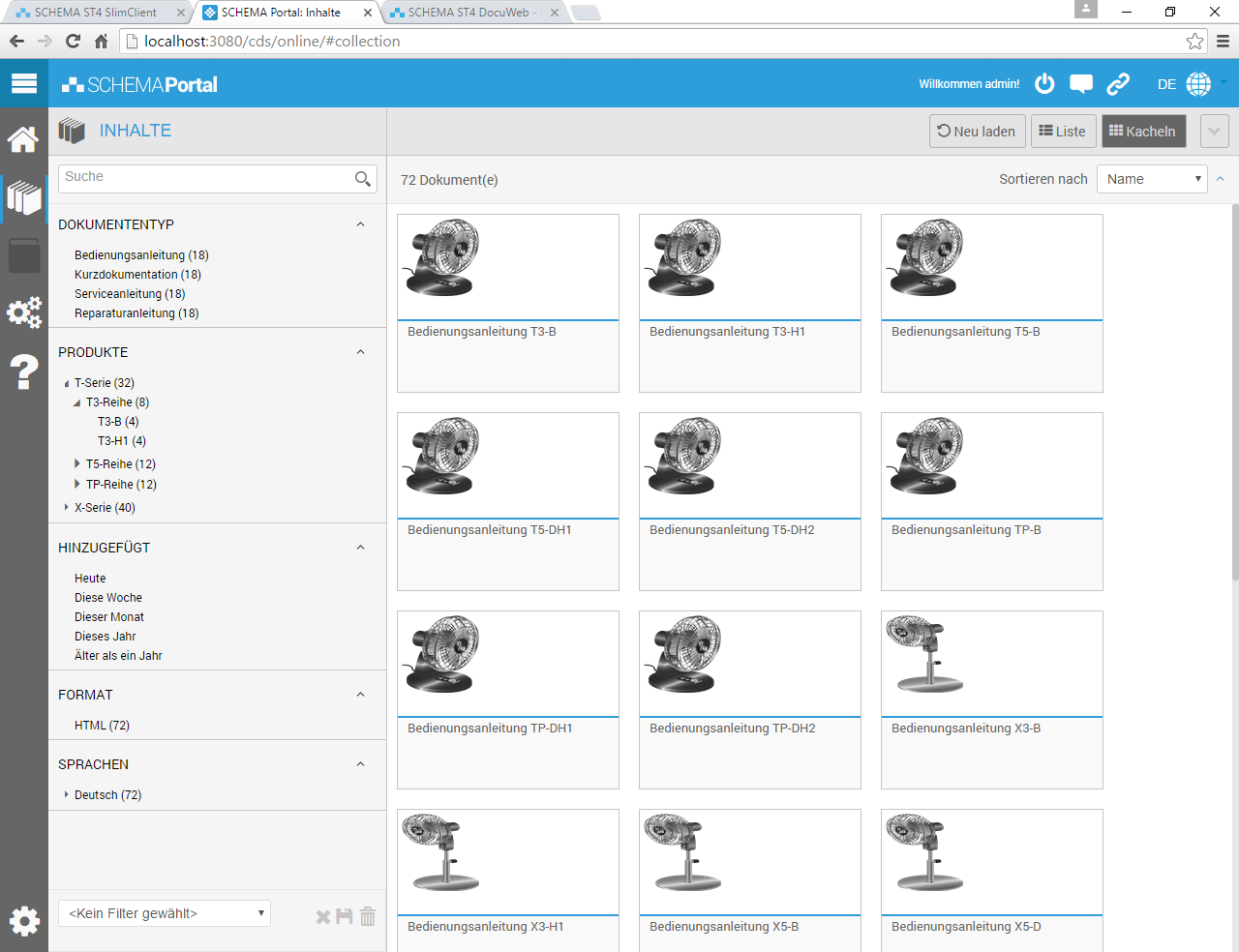
Die Taxonomien können im SCHEMA CDS zur Filterung auf Paketebene.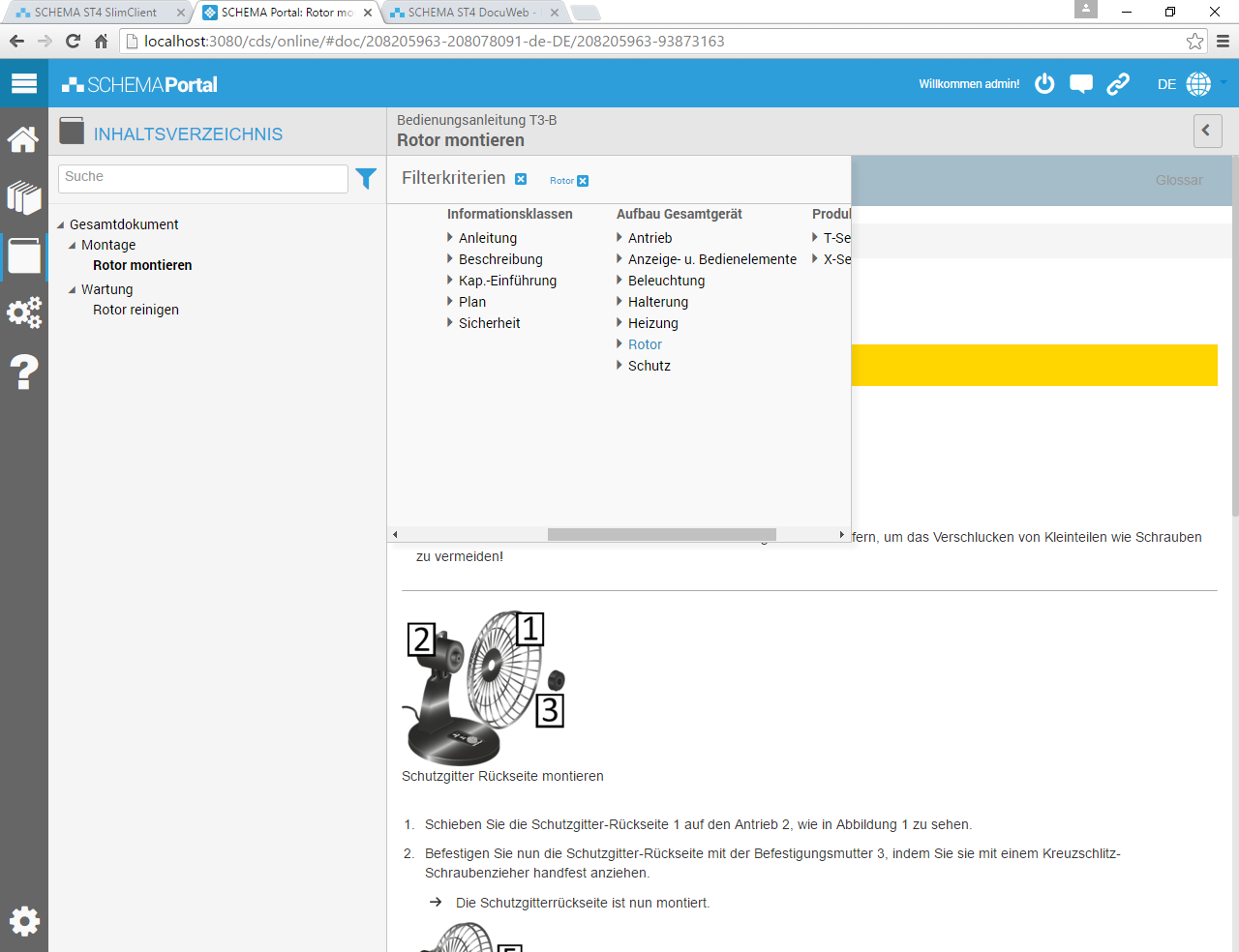
Aber auch zum Filtern innerhalb von Dokumenten verwendet werden.

Sie planen die Einführung einer Software für Technische Dokumentation? Mit unserem neuesten White Paper unterstützen …

Seit einigen Jahren fällt in der Softwaredokumentation immer wieder das Stichwort Docs-as-Code. Vor allem in agilen S…

Frohe Weihnachten und einen guten Rutsch ins Jahr 2024!