Künstliche Intelligenz in der Technischen Dokumentation, Teil 2
Schon heutzutage ist Künstliche Intelligenz in der Technischen Dokumentation verbreitet. Bei welchen Arbeiten in der Technischen Dokumentation Künstliche Intelligenz bereits zum Einsatz kommt, welche Vorteile die neue Technologie mit sich bringt und wo deren Grenzen liegen, erklären uns Fabienne Lange und Eva-Maria Meier, Projektmanagerinnen bei der plusmeta GmbH, im zweiten Teil dieses Interviews. Der erste Teil des Interviews zu KI-Methoden ist auf dem Blog von plusmeta zu finden. Die plusmeta GmbH mit Sitz in Karlsruhe ist Pionierin für künstliche Intelligenz in der Technischen Dokumentation und Partner von Quanos.

Schon heutzutage ist Künstliche Intelligenz in der Technischen Dokumentation verbreitet. Bei welchen Arbeiten in der Technischen Dokumentation Künstliche Intelligenz bereits zum Einsatz kommt, welche Vorteile die neue Technologie mit sich bringt und wo deren Grenzen liegen, erklären uns Fabienne Lange und Eva-Maria Meier, Projektmanagerinnen bei der plusmeta GmbH, im zweiten Teil dieses Interviews. Der erste Teil des Interviews zu KI-Methoden ist auf dem Blog von plusmeta zu finden. Die plusmeta GmbH mit Sitz in Karlsruhe ist Pionierin für künstliche Intelligenz in der Technischen Dokumentation und Partner von Quanos.
Frau Lange, Frau Meier, im ersten Teil unseres Interviews haben Sie uns erklärt, wie Künstliche Intelligenz funktioniert und welche Verfahren in der Technischen Dokumentation bereits zum Einsatz kommen, also zum Beispiel Machine Learning und regelbasierte Verfahren. Jetzt würden uns konkrete Anwendungsfälle interessieren. Können Sie ein paar davon beschreiben?
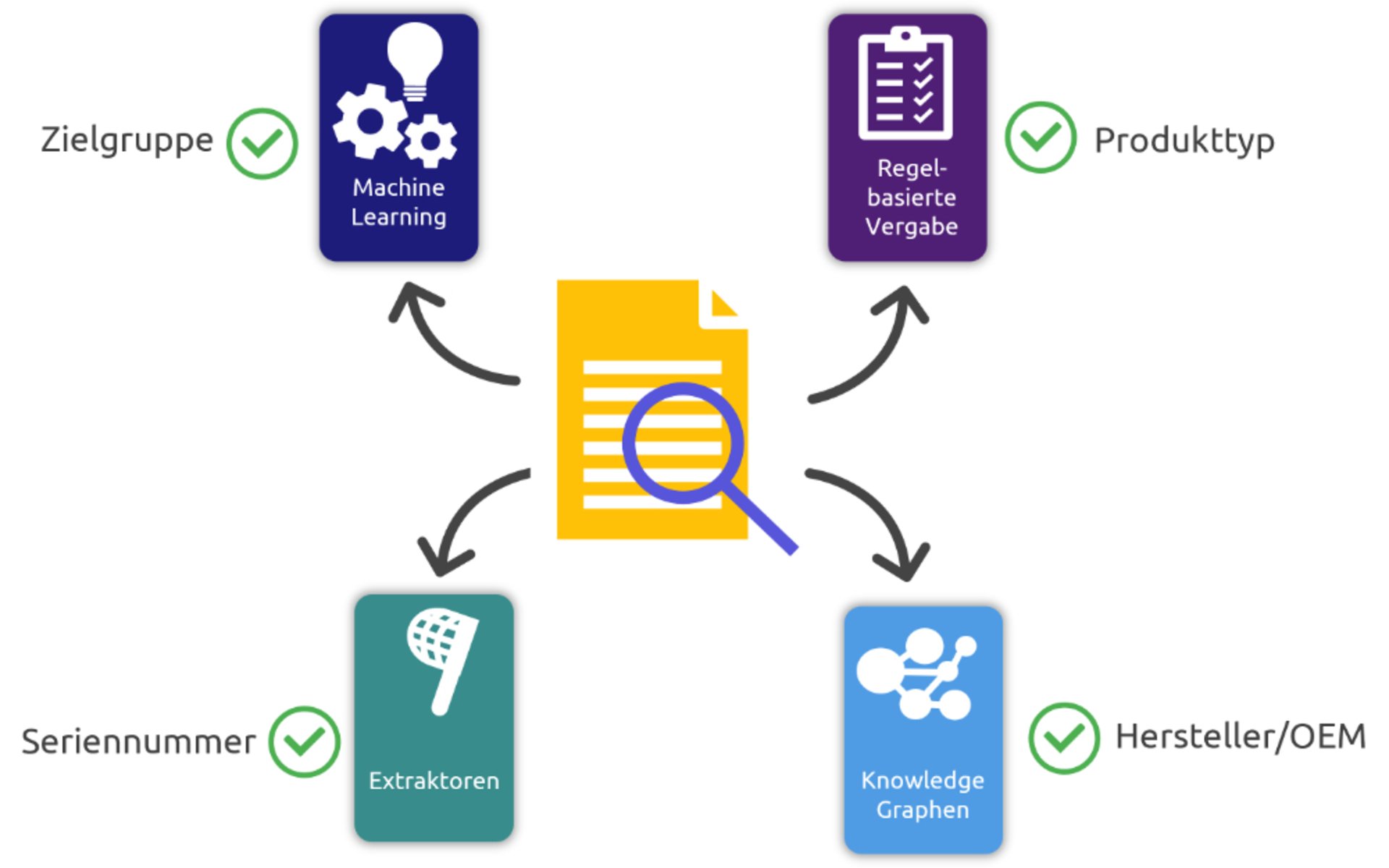
Fabienne Lange: Der für uns wichtigste Anwendungsfall ist die Metadatenerkennung. Moderne Anwendungen wie Content Delivery Portale sind auf passende Metadaten angewiesen, damit Anwender zielgerichtet suchen und unter den Treffern die gewünschte Antwort finden können. Aber auch Standards im Umfeld der Technischen Kommunikation fordern Metadaten, so etwa die VDI 2770 oder iiRDS. Die KI-Unterstützung ist hier ein richtiger Türöffner. In der Technischen Dokumentation gibt es in der Regel große Mengen an Bestandsdaten. Müsste man diese händisch ohne Unterstützung aufbereiten, wäre das zeitlich einfach nicht leistbar und auch wirtschaftlich nicht sinnvoll.
Beispielsweise können mit der Regelbasierten Erkennung über das Vorkommen von Wörtern oder Synonymen im Text Metadaten erkannt werden. Der Vorteil hier ist, dass dafür kein zuvor aufwändig trainiertes Machine-Learning-Modell notwendig ist. Damit die regelbasierte Erkennung funktioniert, sollten die Wörter oder Synonyme aber explizit im Text vorkommen, wie es beispielsweise beim „Produkttyp“ üblich ist.
Spielen hier auch Knowledge Graphen eine Rolle?
Fabienne Lange: Ja, auf jeden Fall. Als Unterkategorien der Regelbasierten Erkennung können auch Knowledge Graphen und Extraktoren eingesetzt werden, um Metadaten zu erkennen. Knowledge Graphen können anhand von Produktwissen weitere Metadaten herleiten, die selbst gar nicht im Text vorkommen. Ein Beispiel dafür ist etwa der Hersteller eines Produktes, der über den Knowledge Graph mit dem Produkt verbunden ist.
Extraktoren hingegen eignen sich gut, um Metadaten zu erkennen, die bestimmten Mustern folgen. Beispiele dafür sind etwa Seriennummern, Auftragsnummern oder Datumsangaben. Das funktioniert auch dann, wenn es keine Auswahlliste zum Abgleich gibt.
Und wie sieht es mit Machine Learning aus, wenn es um die Erkennung von Metadaten geht?
Fabienne Lange: Natürlich hat auch das Machine Learning seine Daseinsberechtigung im Bereich der Metadatenerkennung. Zwar ist hier vorab ein Training mit Beispieldaten notwendig, dafür können mithilfe von Machine Learning Metadaten vorhergesagt werden, die mit den anderen Methoden oft nur schwer auffindbar wären. Das sind etwa Metadaten wie die Zielgruppe, das Informationsthema oder der Topictyp. Ein Text für einen Experten ist beispielsweise anders geschrieben als ein Text für einen Laien. Und in einem Topictyp „Aufgabe“ sind mehr anleitende Texte enthalten als in einem „Konzept“. Diese Auffälligkeiten können von einem Machine-Learning-Modell erkannt werden. Das ermöglicht es, auch Metadaten vorherzusagen, die nicht anhand einzelner Wortvorkommen festgemacht werden können. Insgesamt haben alle Verfahren ihre Stärken und Schwächen. Kombiniert man sie, kann man zu sehr guten Ergebnissen bei der Metadatenerkennung kommen.
Eva-Maria Meier: Eine weitere spannende Anwendungsmöglichkeit ist die Dokumentsegmentierung bzw. die Erkennung von Kapiteln in langen Dokumenten. Sie basiert ebenfalls auf Metadatenerkennung. Häufig wird beispielsweise die Produktlebenszyklusphase als Segmentierungskriterium verwendet. Die Dokumente werden dabei in kleine Schnipsel aufgeteilt und klassifiziert. Dasselbe wird auch noch mehrmals mit ein bisschen Versatz gemacht. Dann werden alle Ergebnisse übereinandergelegt. Überall wo die KI dann anfängt, unsicher zu werden um welche Produktlebenszyklusphase es sich handelt oder wo es Wechsel gibt, ist wahrscheinlich eine Kapitelgrenze.
Wir haben auch von der Ähnlichkeitsanalyse gehört. Können Sie dazu noch etwas sagen?
Die Ähnlichkeitsanalyse kann helfen, Dubletten und Varianten zu finden, z. B. beim Aufräumen des Redaktionssystems oder beim Durchforsten von Zuliefererdokumentationsbergen für eine Migration. Auch hier kann man auf der Metadatenerkennung aufsetzten und erkannte Metadaten vergleichen. Darüber hinaus ist auch der Vergleich von Wortgruppen hilfreich, um gleichlautende Informationsbausteine zu finden. Mit Deep-Learning könnte man sogar noch einen Schritt tiefer gehen und auch die Bedeutung vergleichen.
Und auch im Sprachmanagement wird KI heutzutage schon verwendet. Beispiele dafür sind die Term-Extraktion und Controlled-Language-Checker, die in erster Linie regelbasierte Verfahren verwenden. Und dann gibt es natürlich auch noch den aktuell stark wachsenden Bereich der maschinellen Übersetzung, der mithilfe von Deep-Learning-Verfahren, Texte automatisiert übersetzen kann.
Wenn man an die Vorteile von Künstlicher Intelligenz denkt, kommt einem wahrscheinlich als erstes die Zeitersparnis in den Sinn. Welche zusätzlichen Vorteile bietet die neue Technologie?
Eva-Maria Meier: Die KI kann stupide Tätigkeiten übernehmen. Gerade wenn große Bestandsdatenberge zu verarbeiten sind, kann KI den Arbeitsprozess angenehmer gestalten. Dann muss man als Redakteur nur noch die Vorhersage überprüfen. Die KI wird bei ihren Prognosen auch nicht müde und liefert immer gleichbleibende Qualität. Sie urteilt außerdem objektiv nach den gelernten Kriterien. Der größte Vorteil ist aber sicher der bereits vorhin erwähnte Tür-öffner-Effekt. Viele Anwendungen sind auf Metadaten angewiesen. Diese manuell für große Bestandsdatenberge nachzupflegen kann auch schlicht unmöglich sein.
Was sind die Schwächen von Künstlicher Intelligenz? Wo kommt sie an ihre Grenzen? Und was bedeutet das für die Zukunft?
Fabienne Lange: Anfangs wird es häufig als Schwäche empfunden, dass KI-Modelle in manchen Fällen zunächst trainiert und Systeme eingerichtet werden müssen. Das bedeutet zu Beginn einen gewissen Initialaufwand. Betrachtet man aber die mögliche Zeitersparnis durch den Einsatz der KI, so ist dieser oft leicht zu verkraften. Als weiterer Nachteil können die Komplexität und die technologischen Anforderungen von KI-Anwendungen genannt werden. Diese können insbesondere im Bereich des Machine Learning und Deep Learning abschreckend wirken und schwer verständlich sein. Gerade Deep Learning benötigt eine hohe verfügbare Rechenleistung. Durch Cloud-Anwendungen kann das heutzutage aber oft ermöglicht werden. Außerdem sind die Modelle beim Deep-Learning in der Regel eine Blackbox, sodass man nicht immer nachvollziehen kann, wie Ergebnisse zustande kommen.
Eine weitere Schwäche ist insbesondere im Bereich der Technischen Kommunikation relevant: Die Einhaltung rechtlicher Anforderungen. Technische Dokumentation enthält Informationen zur Sicherheit und ist entsprechend wichtig für die rechtliche Absicherung. Werden diese Informationen aufgrund falscher KI-Vorhersagen nicht angezeigt, können Gefahren übersehen werden.
Diese rechtlichen Anforderungen in der Technischen Kommunikation erschweren vollautomatisierte KI-Prozesse. Allerdings gibt es auch hier eine Lösung: Durch das Human-in-the-Loop-Prinzip können Technischen Redakteure in den KI-Prozess miteingebunden werden. So können beispielsweise vorhergesagte Metadaten durch Technischen Redakteur:innen überprüft und abgenommen werden. Durch diese Zusammenarbeit von Mensch und Maschine kann so auch rechtlich abgesichert Zeit eingespart werden.

plusmeta hat ein Forschungsprojekt namens DEEEP ins Leben gerufen, bei dem es um die Entwicklung einer Deep Learning Komponente für die Technische Dokumentation gibt. Bitte erzählen Sie uns doch etwas mehr über dieses Projekt.
Eva-Maria Meier: Im Rahmen des Projekts, das vom Ministerium für Wirtschaft, Arbeit und Tourismus Baden-Württemberg gefördert wird, entwickeln wir eine Deep-Learning-Komponente für plusmeta. Diese KI-Methode wird in der Technischen Dokumentation in der Praxis zum Klassifizieren von Daten bisher nicht eingesetzt – hat aber viel Potential. So können mit Deep-Learning-Verfahren neben Texten auch Bilder klassifiziert werden. Außerdem wollen wir die Initialaufwände bei neuen Projekten senken, indem wir Clustering für Trainingsdaten und ein Metadatenvorschlagswesen anbieten. Bei der Vorhersagengenauigkeit wollen wir dank Deep-Learning neue Maßstäbe setzen. Das ist möglich, weil Deep-Learning neben den Wörtern selbst auch Kontexte berücksichtigt und damit ein tiefergehendes Textverständnis mitbringt.
Für das Finetuning der Methoden auf die spezifischen Belange der Technischen Kommunikation brauchen wir sehr große Datenmengen. Die Daten eines Unternehmens reichen nicht aus. Wir sind daher auf Datenlieferanten aus der Wirtschaft angewiesen. Interessenten können sie gerne per Mail an deeep@plusmeta.de melden. Im Gegenzug gibt es brandaktuelle Forschungsergebnisse und die Möglichkeit neue Features zu testen.
Das Interview führte Susanne Meier von Quanos Content Solutions.
Andere Artikel von Quanos
Das könnte Sie auch interessieren

„Für eine kleine Redaktion lohnt sich das nicht“ – Was ein Kunde dazu sagt…
Vor kurzem hatten wir hier ein Interview zum Thema ST4 in Ein-Personen-Redaktion mit Michael Rohde von der iTAC Softw…